Project Details
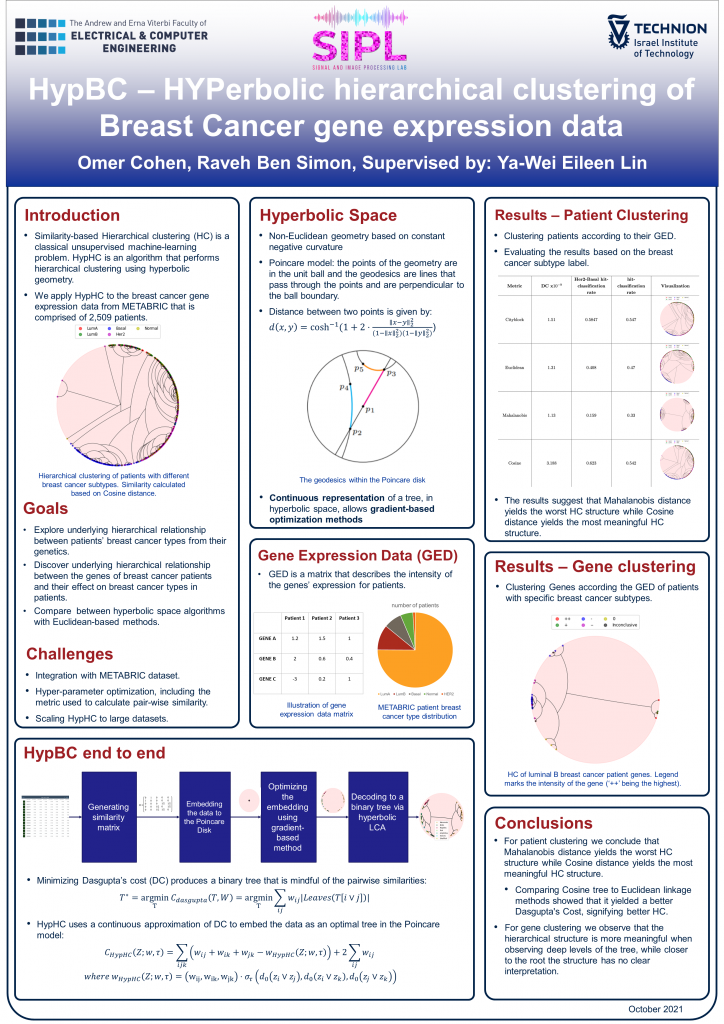
Project DetailsSimilarity-based Hierarchical clustering (HC) is a classical unsupervised machine-learning problem. HypBC is an algorithm that performs hierarchical clustering using hyperbolic geometry.
We applied HypBC to the METABRIC dataset, comprised of the gene-expression data of multiple types of Breast Cancer patients.
HypBC consists of five main stages: Data preprocessing; Generating a similarity matrix; Embedding the datapoints in hyperbolic space; Performing continuous optimization to minimize a cost function based on the similarity matrix; Decoding the discrete tree from the embedding.
In our work to create HypBC we tackled challenges of integrating the HypHC algorithm with the METABRIC dataset. We also addressed the challenge of scaling HypHC to larger datasets which in its original form had high memory complexity.
We discovered that in order to perform HC on the patients, based on their gene-expression data, the best similarity metric is Cosine distance, followed by euclidean distance and Cityblock distance. Mahalanobis distance performed considerably worse than the aforementioned metric.
Furthermore, using the Cosine similarity, HypBC outperformed the baseline linkage methods we tested according to the Dasgupta's cost of the resulting hierarchical structure.
When applying HypBC to do HC of the gene-expression data based on the patients' cancer sub-types we learned that it performs quite well for the deeper hierarchies of the resulting tree, yielding distinct subtrees that are homogeneous. The higher hierarchies of the resulting trees showed illogical relations between their subtrees, thus indicating a bad performance of the system.