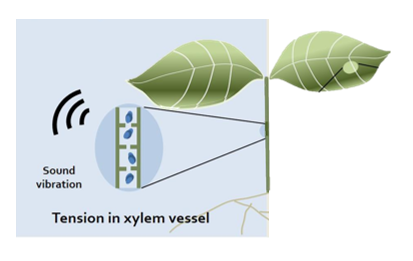
This work explores the classification of plant-emitted ultrasonic sounds using machine learning, adapting speech-processing models to a new biological domain. The dataset, provided by Tel Aviv University, consists of 16,000 samples of 2ms audio recordings (sampled at 500 kHz) from plant species, including tomato, corn, cacti, wheat, lamium, tobacco, and grapevine. These recordings included conditions like “cut” and “dry,” and served as a basis for species and condition classification.
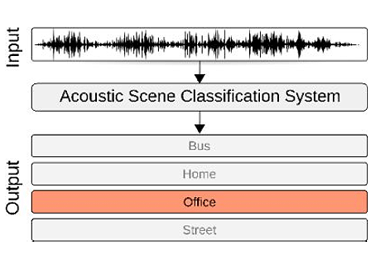
We aim to boost classification performance (evaluated using F1 and accuracy metrics) using advanced model architectures and self-supervised (SS) representations.

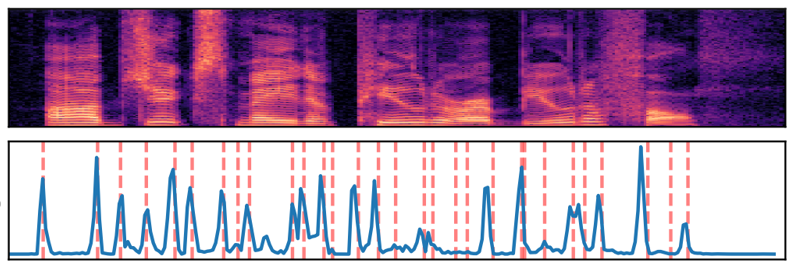
 How Does a Lexical Stress Look like?
How Does a Lexical Stress Look like?